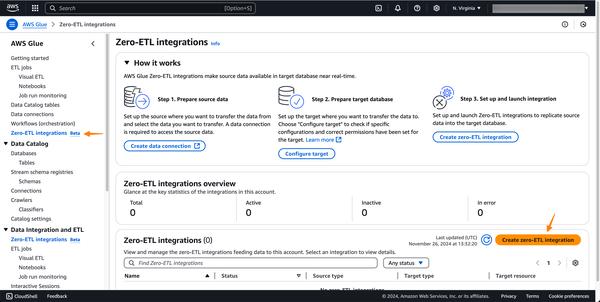
Microsoft announced that GitHub uses Azure Functions to scale on demand. GitHub leverages the Azure Functions Flex Consumption plan, which supports long function execution times, private networking, instance size selection, and concurrency control.
One interesting aspect of the story is how GitHub encountered scalability issues with its in-house data pipeline. Processing 700 terabytes of data daily, the existing system struggled to keep up, leading to performance and reliability concerns.
The choice of Azure Functions Flex Consumption is an intriguing solution. Its ability to scale automatically based on demand, support for long function execution times, and advanced networking capabilities make it well-suited for large data processing scenarios.
It's particularly noteworthy how GitHub achieved a throughput of 1.6 million events per second using Azure Functions Flex Consumption. This highlights the scalability and performance of the platform.
GitHub's journey to improve its data pipeline is a testament to the challenges organizations face as their data volumes grow. Utilizing Azure Functions Flex Consumption provides a scalable and performant solution that can handle the demands of big data processing.
Overall, the GitHub story serves as an excellent example of how Azure Functions empowers organizations to overcome scalability challenges and achieve high performance in data processing.