Amazon announced the availability of Amazon Bedrock Model Distillation in preview, which automates the process of creating a distilled model for your specific use case by generating responses from a large foundation model (FM) called a teacher model and fine-tuning a smaller FM called a student model with the generated responses. It uses data synthesis techniques to improve the response from the teacher model. Amazon Bedrock then hosts the final distilled model for inference, giving you a faster and more cost-efficient model with accuracy close to the teacher model, for your use case. I'm really impressed with this new feature. I think it will be very helpful for customers who are looking to use generative AI models but are concerned about latency and cost. By distilling a large model into a smaller one, customers can reduce latency and cost while maintaining accuracy. I think this feature will be a game-changer in the field of generative AI.
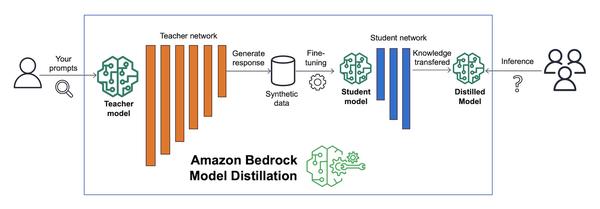
Build faster, more cost-efficient, highly accurate models with Amazon Bedrock Model Distillation (preview)
AWS