Amazon has announced the availability of the new Amazon EC2 Trn2 instances and Trn2 UltraServers, its most powerful EC2 compute options for machine learning (ML) training and inference. Powered by the second generation of AWS Trainium chips (AWS Trainium2), Trn2 instances are 4x faster, have 4x more memory bandwidth, and 3x more memory capacity than the first-generation Trn1 instances. They offer 30-40% better price performance than current-generation GPU-based EC2 P5e and P5en instances. Each Trn2 instance features 16 Trainium2 chips, 192 vCPUs, 2 TiB of memory, and 3.2 Tbps of Elastic Fabric Adapter (EFA) v3 network bandwidth with up to 50% lower latency. Trn2 UltraServers, a new offering, feature 64 Trainium2 chips connected with a high-bandwidth, low-latency NeuronLink interconnect, for peak performance on frontier foundation models. Tens of thousands of Trainium chips already power Amazon and AWS services. Over 80,000 AWS Inferentia and Trainium1 chips supported the Rufus shopping assistant on Prime Day. Trainium2 chips power the latency-optimized versions of Llama 3.1 405B and Claude 3.5 Haiku models on Amazon Bedrock. Trn2 instances are available in the US East (Ohio) region and can be reserved using Amazon EC2 Capacity Blocks for ML. Developers can use AWS Deep Learning AMIs, preconfigured with frameworks like PyTorch and JAX. Existing AWS Neuron SDK apps can be recompiled for Trn2. The SDK integrates with JAX, PyTorch, and libraries like Hugging Face, PyTorch Lightning, and NeMo. Neuron includes optimizations for distributed training and inference with NxD Training and NxD Inference, and supports OpenXLA, enabling PyTorch/XLA and JAX developers to leverage Neuron's compiler optimizations.
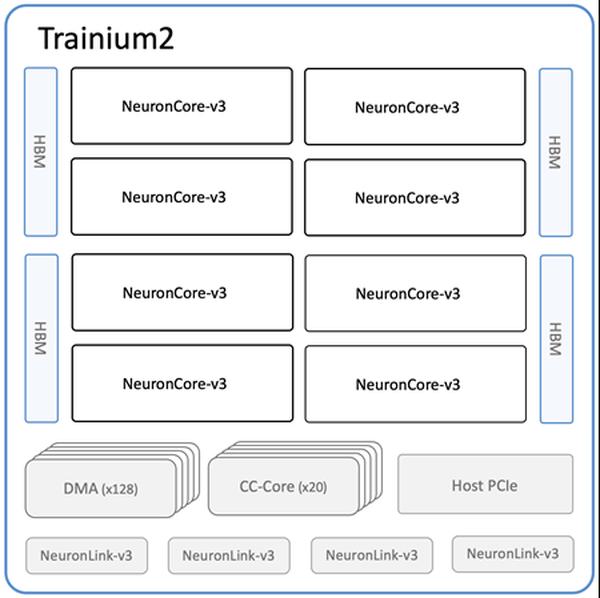
Amazon EC2 Trn2 Instances and Trn2 UltraServers Now Available for AI/ML Training and Inference
AWS