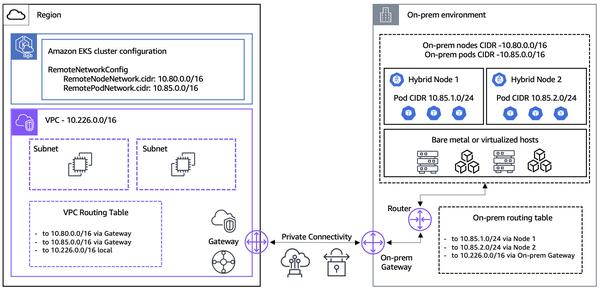
Amazon Data Firehose introduces a new capability to capture changes from databases like PostgreSQL, MySQL, and replicate updates to Apache Iceberg tables on Amazon S3. This offers a simple, end-to-end solution for streaming database updates without impacting transaction performance. Users can set up a Data Firehose stream in minutes to deliver change data capture (CDC) updates from their databases. They can now easily replicate data from different databases into Iceberg tables on Amazon S3 and use up-to-date data for large-scale analytics and machine learning (ML) applications. AWS enterprise customers typically use hundreds of databases for transactional applications. To perform large-scale analytics and ML on the latest data, they want to capture changes made in databases, such as when records are inserted, modified, or deleted in a table, and deliver updates to their data warehouse or Amazon S3 data lake in open-source table formats like Apache Iceberg. Many customers develop extract, transform, and load (ETL) jobs to periodically read from databases. However, ETL readers impact database transaction performance, and batch jobs can add hours of delay before data is available for analytics. To mitigate this, customers want to stream changes made in the database, referred to as a CDC stream. With this new data streaming capability, Data Firehose adds the ability to acquire and continually replicate CDC streams from databases to Apache Iceberg tables on Amazon S3. Users set up a Data Firehose stream by specifying the source and destination. Data Firehose captures and replicates an initial data snapshot and all subsequent changes to the selected database tables as a data stream. To acquire CDC streams, Data Firehose uses the database replication log, reducing the impact on database transaction performance. When the volume of database updates fluctuates, Data Firehose automatically partitions the data and persists records until delivery. Users don't need to provision capacity or manage clusters. Data Firehose can also automatically create Apache Iceberg tables using the same schema as the database tables during initial stream creation and automatically evolve the target schema based on source schema changes. As a fully managed service, Data Firehose eliminates the need for open-source components, software updates, or operational overhead.
Replicate Changes from Databases to Apache Iceberg Tables Using Amazon Data Firehose (in Preview)
AWS