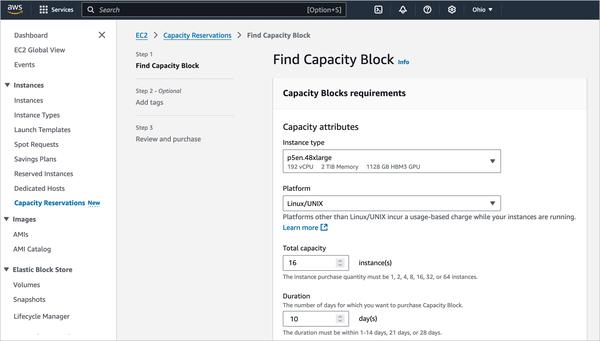
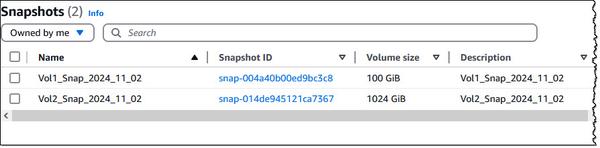
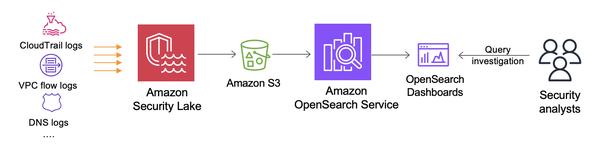
Google published a blog post about fine-tuning large language models, focusing on Gemma. The article provides an overview of the process from beginning to end, starting with dataset preparation and moving through fine-tuning an instruction-tuned model.
I found it particularly interesting how they emphasized the importance of data preparation and hyperparameter optimization. It's clear that these aspects can have a significant impact on the model's performance, and it's essential to consider them carefully.
One challenge I often see in my work is ensuring that chatbots understand nuanced language, handle complex dialogues, and deliver accurate responses. The approach outlined in this blog post seems to offer a promising solution to this problem.
I would be interested in learning more about the specifics of the hyperparameter tuning process. For example, what specific parameters were tuned, and how were the optimal values determined? A more in-depth discussion of this aspect would be very helpful.
Overall, I found this blog post to be very informative and provide a helpful overview of fine-tuning large language models. I think this information will be valuable to anyone looking to build chatbots or other language-based applications.