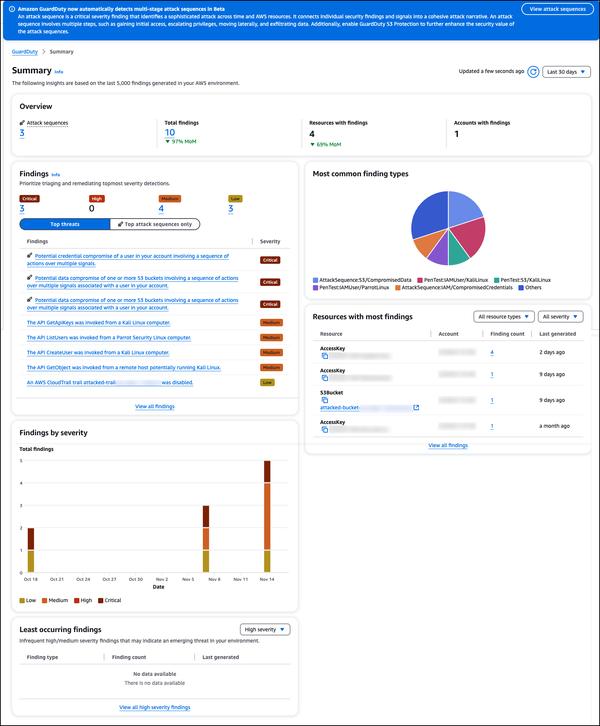
Amazon Bedrock has announced new RAG evaluation and LLM-as-a-judge capabilities, streamlining the testing and improvement of generative AI applications. Amazon Bedrock Knowledge Bases now supports RAG evaluation, allowing you to run an automatic knowledge base evaluation to assess and optimize Retrieval Augmented Generation (RAG) applications. This uses a large language model (LLM) to compute evaluation metrics, enabling comparison of different configurations and tuning for optimal results. Amazon Bedrock Model Evaluation now includes LLM-as-a-judge, allowing testing and evaluation of other models with human-like quality at a fraction of the cost and time. These capabilities provide fast, automated evaluation of AI applications, shortening feedback loops and speeding improvements. Evaluations assess quality dimensions like correctness, helpfulness, and responsible AI criteria such as answer refusal and harmfulness. Results provide natural language explanations for each score, normalized from 0 to 1 for easy interpretation. Rubrics and judge prompts are published in the documentation for transparency.
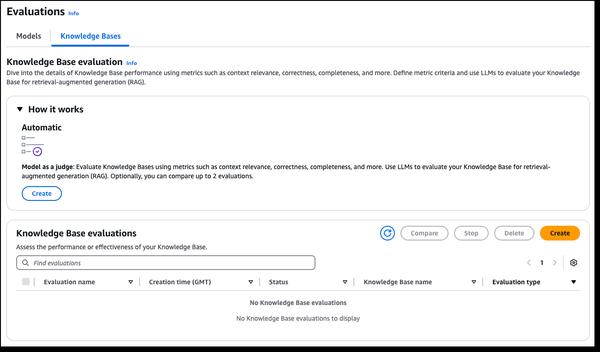
New RAG Evaluation and LLM-as-a-Judge Capabilities in Amazon Bedrock
AWS