Meta has released Llama 3.2 models, a groundbreaking family of language models with enhanced capabilities, broader applicability, and multimodal image support, now available in Amazon Bedrock. This release represents a significant advancement in large language models (LLMs), offering enhanced capabilities and broader applicability across various use cases.
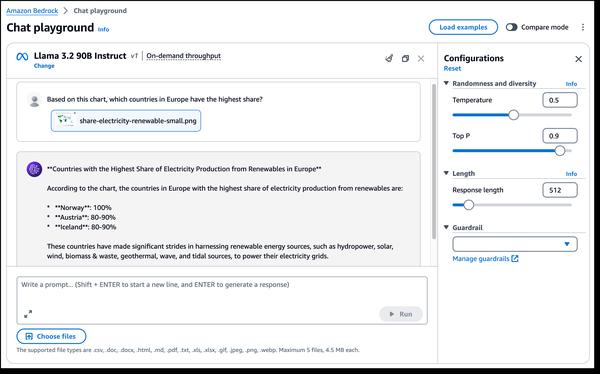
One of the most exciting aspects of Llama 3.2 is the introduction of multimodal vision capabilities. The new 90B and 11B models are designed for image understanding and visual reasoning, opening up new possibilities for applications such as image captioning, image-text retrieval, and visual question answering. These capabilities could revolutionize how we interact with and utilize images across different domains.
Additionally, Llama 3.2 offers lightweight models suitable for edge devices. The 1B and 3B models are designed to be resource-efficient with reduced latency and improved performance, making them ideal for applications on devices with limited capabilities. This could lead to the development of more intelligent AI-powered writing assistants and customer service applications on mobile devices.
Furthermore, Llama 3.2 is built on top of the Llama Stack, a standardized interface for building canonical toolchain components and agentic applications, making building and deploying easier than ever. This provides developers with a standardized and efficient way to integrate Llama models into their applications.
Overall, the release of Llama 3.2 marks a significant step forward in the field of large language models. Its enhanced capabilities and broader applicability open up new possibilities for a wide range of use cases, from image understanding and visual reasoning to edge applications. As generative AI technology continues to evolve, we can expect further innovations and transformative applications from models like Llama 3.2.