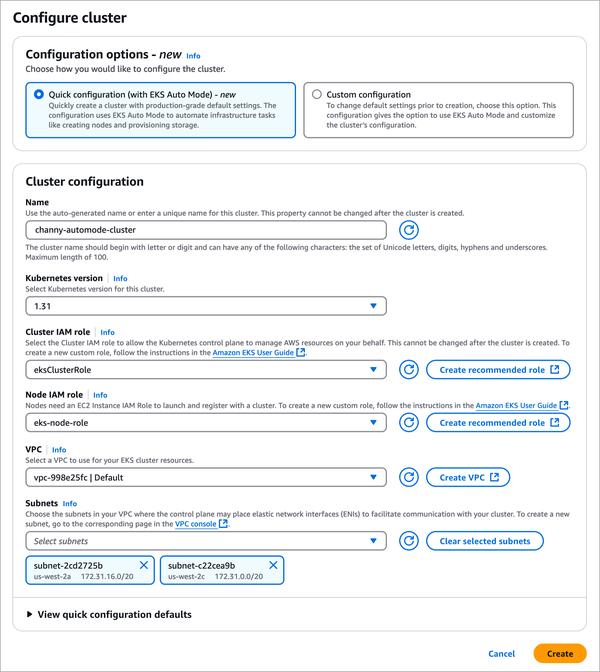
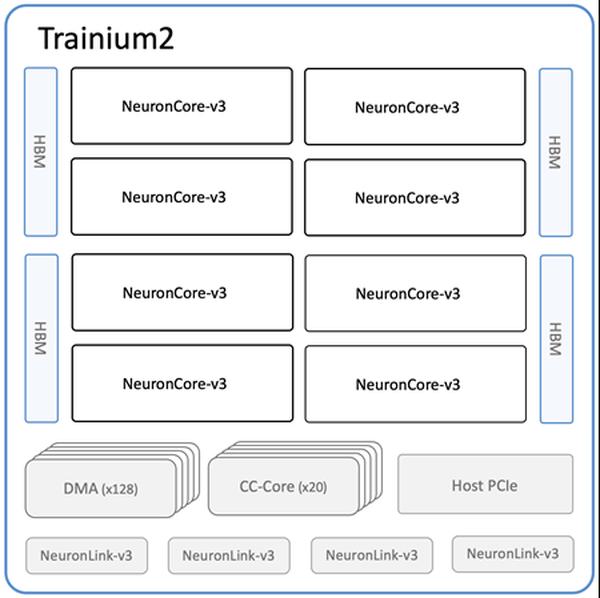
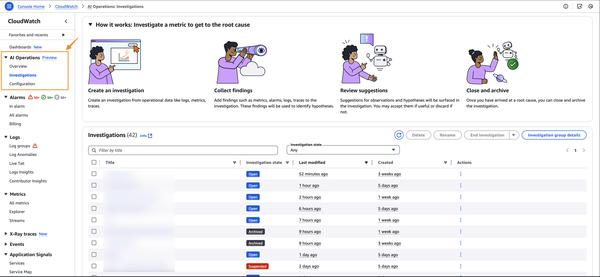
Google Cloud published a blog post discussing the choices developers face when selecting an infrastructure to host AI models, focusing specifically on large language models (LLMs). The article highlights the relative merits and drawbacks of self-managed solutions like Google Kubernetes Engine (GKE) and fully managed solutions like Vertex AI.
One interesting aspect the article emphasizes is the importance of understanding project requirements and needs when deciding on LLM infrastructure. For teams prioritizing ease of use and speed of implementation, Vertex AI presents a compelling solution with managed features like automatic scaling and security updates. On the other hand, GKE offers greater control, customization, and potential cost savings for organizations with strong DevOps teams and specific requirements.
The article also provides a practical example of a Java application deployed on Cloud Run for efficient LLM inference. This example illustrates how organizations can leverage Cloud Run's serverless infrastructure to simplify deployments and achieve scalability. Furthermore, the article delves into the steps of deploying an open-source model on GKE using vLLM, providing a comprehensive guide for organizations looking to host their own models.
Overall, the article offers an insightful analysis of the considerations involved in choosing LLM infrastructure. By highlighting the pros and cons of both Vertex AI and GKE, the article equips developers, DevOps engineers, and IT decision-makers with the knowledge to make informed decisions that align with their specific needs. The balance between ease of use and customization, as illustrated in the article, is crucial for successful LLM deployment and harnessing the power of generative AI.